Posts
Thesis now published – Troublemakers in the Streets?
My thesis “Troublemakers in the Streets? A Framing Analysis of Newspaper Coverage of Protest in the UK 1992-2017” is available on the website of the University of Glasgow since last week. It scrutinises how mainstream news media in the United Kingdom have framed domestic protest over the last three decades. I will (try to) publish parts of this research for different audiences over the next year. But here I wanted to summarise a few key points.
Let users choose which plot you want to show
If you have build your homepage using blogdown, it’s actually quite simple to integrate Javascript snippets in it. While this is mentioned in the book “blogdown: Creating Websites with R Markdown”, it still took me a little bit to undertstand how it works.
As an example, let’s make different versions of a simple plot and let the user decide which one to display. First I make the plots and save them in a sub-directory:
Get all your packages back on R 4.0.0
R 4.0.0 was released on 2020-04-24. Among the many news two stand out for me: First, R now uses stringsAsFactors = FALSE by default, which is especially welcome when reading in data (e.g., via read.csv) and when constructing data.frames. The second news that caught my eye was that all packages need to be reinstalled under the new version.
This can be rather cumbersome if you have collected a large number of packages on your machine while using R 3.
You R My Valentine 2.0!
Like last year I wanted to make something special for my wonderful R-Lady. This year the main work was done by the very talented Will Chase, who makes wonderful aRt including the animation this post is based on. All I did to change the original animation was to cut it into a heart shape and carve our initials into the center. Enjoy:
library(dplyr) library(poissoned) library(gganimate) # generate points pts <- poisson_disc(ncols = 150, nrows = 400, cell_size = 2, xinit = 150, yinit = 750, keep_idx = TRUE) %>% arrange(idx) # generate heart shape hrt_dat <- data.
(Much) faster unnesting with data.table
Today I was struggling with a relatively simple operation: unnest() from the tidyr package. What it’s supposed to do is pretty simple. When you have a data.frame where one or multiple columns are lists, you can unlist these columns while duplicating the information in other columns if the length of an element is larger than 1.
library(tibble) df <- tibble( a = LETTERS[1:5], b = LETTERS[6:10], list_column = list(c(LETTERS[1:5]), "F", "G", "H", "I") ) df ## # A tibble: 5 x 3 ## a b list_column ## <chr> <chr> <list> ## 1 A F <chr [5]> ## 2 B G <chr [1]> ## 3 C H <chr [1]> ## 4 D I <chr [1]> ## 5 E J <chr [1]> library(tidyr) unnest(df, list_column) ## # A tibble: 9 x 3 ## a b list_column ## <chr> <chr> <chr> ## 1 A F A ## 2 A F B ## 3 A F C ## 4 A F D ## 5 A F E ## 6 B G F ## 7 C H G ## 8 D I H ## 9 E J I I came across this a lot while working on data from Twitter since individual tweets can contain multiple hashtags, mentions, URLs and so on, which is why they are stored in lists.
Introducing rwhatsapp
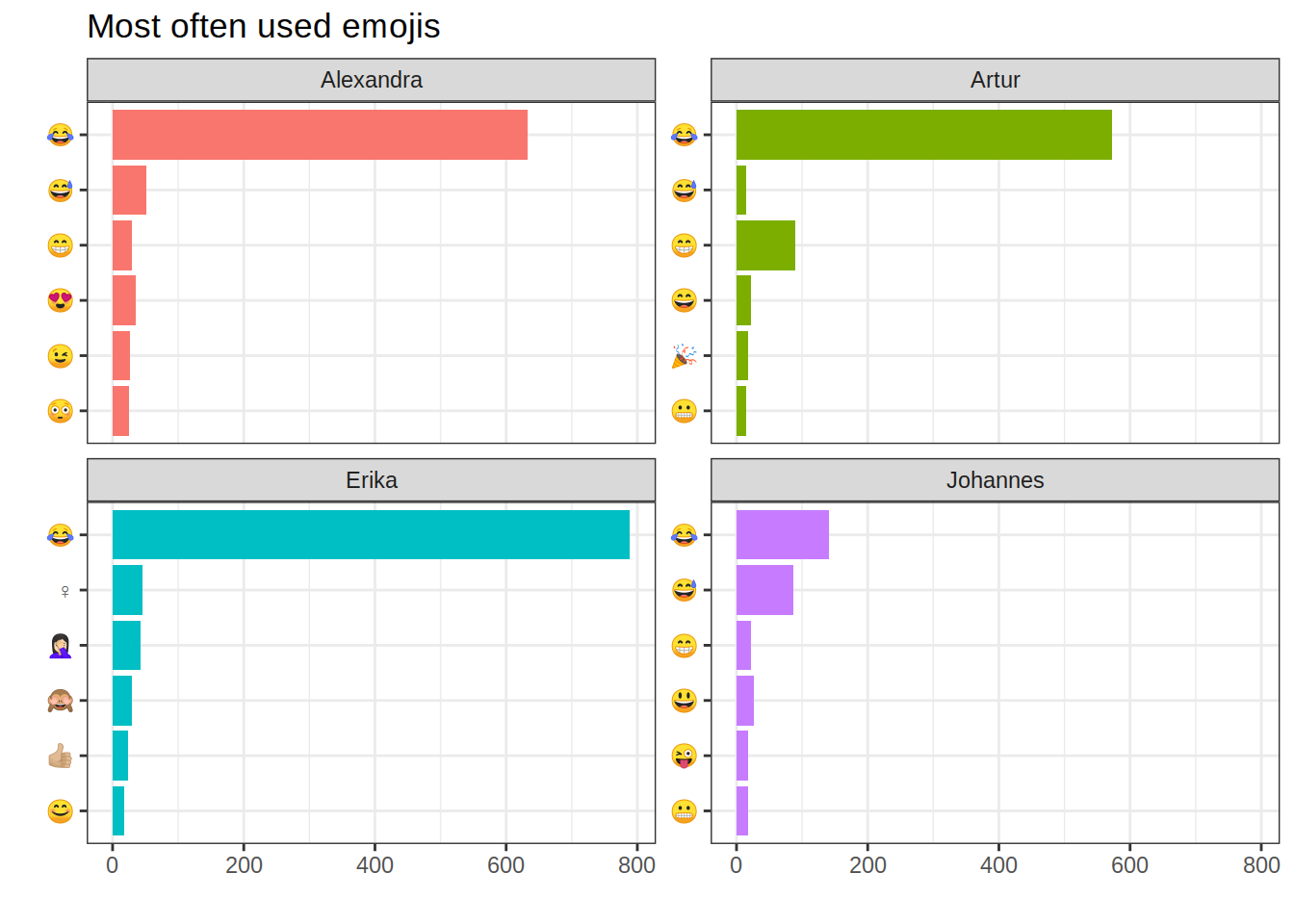
I’m happy to announce that rwhatsapp is now on CRAN. After being tested by users on GitHub for a year now, I decided it is time to make the package available to a wider audience. The goal of the package is to make working with ‘WhatsApp’ chat logs as easy as possible.
‘WhatsApp’ seems to become increasingly important not just as a messaging service but also as a social network—thanks to its group chat capabilities.
You R my Valentine!
Today is Valentine’s Day. And since both I and my sweetheart are R enthusiasts, here is how to say “I love you” using a statistical programming language:
library("dplyr")
library("gganimate")
library("ggplot2")
hrt_dat <- data.frame(t = seq(0, 2 * pi, by = 0.01)) %>%
bind_rows(data.frame(t = rep(max(.$t), 300))) %>%
mutate(xhrt = 16 * sin(t) ^ 3,
yhrt = 13 * cos(t) - 5 * cos(2 * t) - 2 * cos(3 * t) - cos(4 * t),
frame = seq_along(t)) %>%
mutate(text = ifelse(frame > 300, " J", "")) %>%
mutate(text = ifelse(frame > 500, "A J", text)) %>%
mutate(text = ifelse(frame > 628, "A + J", text)) %>%
mutate(texty = 0, textx = 0)
ggplot(hrt_dat, aes(x = xhrt, y = yhrt)) +
geom_line(colour = "#C8152B") +
geom_polygon(fill = "#C8152B") +
geom_text(aes(x = textx, y = texty, label = text),
size = 18,
colour = "white",
vjust = "center") +
theme_void() +
transition_reveal(frame)
Smarter Wordclouds
Some time ago, I saw a presentation by Wouter van Atteveldt who showed that wordclouds aren’t necessarily stupid. I was amazed since wordclouds were one of the first things I ever did in R and they are still often shown in introductions to text analysis. But the way they are mostly done is, in fact, not very informative. Because the position of the individual words in the cloud do not mean anything, the only information communicated is through the font size and sometimes font colour of the words.
(Mis)using Discourse Network Analyzer for manual coding
For my PhD project, I want to use Supervised Machine Learning (SML) to replicate my manual coding efforts onto a larger data set. That means, however, that I need to put in some manual coding effort before the SML algorithms can do their magic!
I used a number of programs already to analyse texts by hand, and they all come with their up- and downsides. A while ago I already coded articles in order to train an SML algorithm and did so having a PDF with the text opened on the left side of my screen and an Excel file with my category system on the right side.
LexisNexisTools. My first `R` package
My PhD supervisor once told me that everyone doing newspaper analysis starts by writing code to read in files from the ‘LexisNexis’ newspaper archive. However, while I do recommend this exercise, not everyone has the time.
These are the first words of the introduction to my first R package, LexisNexisTools. My PhD supervisor was also my supervisor for my master dissertation and he said these words before he gave me my very first book about R.