I’m happy to announce that rwhatsapp is now on CRAN.
After being tested by users on GitHub for a year now, I decided it is time to make the package available to a wider audience.
The goal of the package is to make working with ‘WhatsApp’ chat logs as easy as possible.
‘WhatsApp’ seems to become increasingly important not just as a messaging service but also as a social network—thanks to its group chat capabilities.
Furthermore, retrieving chat logs from the Android or iOS app is very straightforward:
Simply choose More in the menu of a chat, then Export chat and export the history to a txt file.



While this is easy enough to do, please make sure to ask other chat participants for consent before working with their data.
Install the package with:
install.packages("rwhatsapp")The package comes with a small sample that you can use to get going.
library("rwhatsapp")
history <- system.file("extdata", "sample.txt", package = "rwhatsapp")
history## [1] "/home/johannes/R/x86_64-pc-linux-gnu-library/3.6/rwhatsapp/extdata/sample.txt"The main function of the package, rwa_read() can handle txt (and zip) files directly, which means that you can simply provide the path to a file to get started:
chat <- rwa_read(history)
chat## # A tibble: 9 x 6
## time author text source emoji emoji_name
## <dttm> <fct> <chr> <chr> <lis> <list>
## 1 2017-07-12 22:35:46 <NA> Messages to … /home/johann… <chr… <chr [0]>
## 2 2017-07-12 22:35:46 <NA> "You created… /home/johann… <chr… <chr [0]>
## 3 2017-07-12 22:35:46 Johanne… <Media omitt… /home/johann… <chr… <chr [0]>
## 4 2017-07-12 22:35:46 Johanne… Fruit bread … /home/johann… <chr… <chr [2]>
## 5 2017-07-13 09:12:46 Test "It's fun do… /home/johann… <chr… <chr [0]>
## 6 2017-07-13 09:16:46 Johanne… Haha it sure… /home/johann… <chr… <chr [1]>
## 7 2018-09-28 13:27:46 Johanne… Did you know… /home/johann… <chr… <chr [0]>
## 8 2018-09-28 13:28:46 Johanne… 😀😃😄😁😆😅😂🤣☺😊😇🙂… /home/johann… <chr… <chr [242…
## 9 2018-09-28 13:30:46 Johanne… 🤷♀🤷🏻♂🙎♀🙎… /home/johann… <chr… <chr [87]>This is really all the package does: bring your chat logs into a nice usable format. But since this isn’t very intresting, I decided to also show you a few quick analysis steps to illustrate what you can do with data obtained in this way. For this, I use one of my own chat logs from a conversation with friends. I won’t share it but you should be able to follow along with your own data.
chat <- rwa_read("/home/johannes/WhatsApp Chat.txt")
chat## # A tibble: 16,816 x 6
## time author text source emoji emoji_name
## <dttm> <fct> <chr> <chr> <lis> <list>
## 1 2015-12-10 19:57:46 Artur K… <Media omitted> /home/jo… <chr… <chr [0]>
## 2 2015-12-10 22:31:46 Erika I… 😂😂😂😂😂😂 /home/jo… <chr… <chr [6]>
## 3 2015-12-11 02:13:46 Alexand… 🙈 /home/jo… <chr… <chr [1]>
## 4 2015-12-11 02:23:46 Johanne… 😂 /home/jo… <chr… <chr [1]>
## 5 2015-12-11 02:24:46 Johanne… Die Petitionen … /home/jo… <chr… <chr [1]>
## 6 2015-12-11 03:51:46 Erika I… Läääuft /home/jo… <chr… <chr [0]>
## 7 2015-12-12 07:49:46 Johanne… <Media omitted> /home/jo… <chr… <chr [0]>
## 8 2015-12-12 07:53:46 Erika I… was macht ihr h… /home/jo… <chr… <chr [0]>
## 9 2015-12-12 07:55:46 Johanne… Alex arbeitet w… /home/jo… <chr… <chr [0]>
## 10 2015-12-12 07:55:46 Johanne… und ich spiele … /home/jo… <chr… <chr [0]>
## # … with 16,806 more rowsYou can see from the size of the resulting data.frame that we write a lot in this group!
Let’s see over how much time we managed to accumulate 16,816 messages.
I use a couple of extra packages for that:
library("dplyr")
library("ggplot2"); theme_set(theme_bw())
library("lubridate")
chat %>%
mutate(day = date(time)) %>%
count(day) %>%
ggplot(aes(x = day, y = n)) +
geom_bar(stat = "identity") +
ylab("") + xlab("") +
ggtitle("Messages per day")
The chat has been going on for a while and on some days there were more than a hundred messages! Who’s responsible for all of this?
chat %>%
mutate(day = date(time)) %>%
count(author) %>%
ggplot(aes(x = reorder(author, n), y = n)) +
geom_bar(stat = "identity") +
ylab("") + xlab("") +
coord_flip() +
ggtitle("Number of messages")
Looks like we contributed more or less the same number of messages, with Erika slightly leading the field.
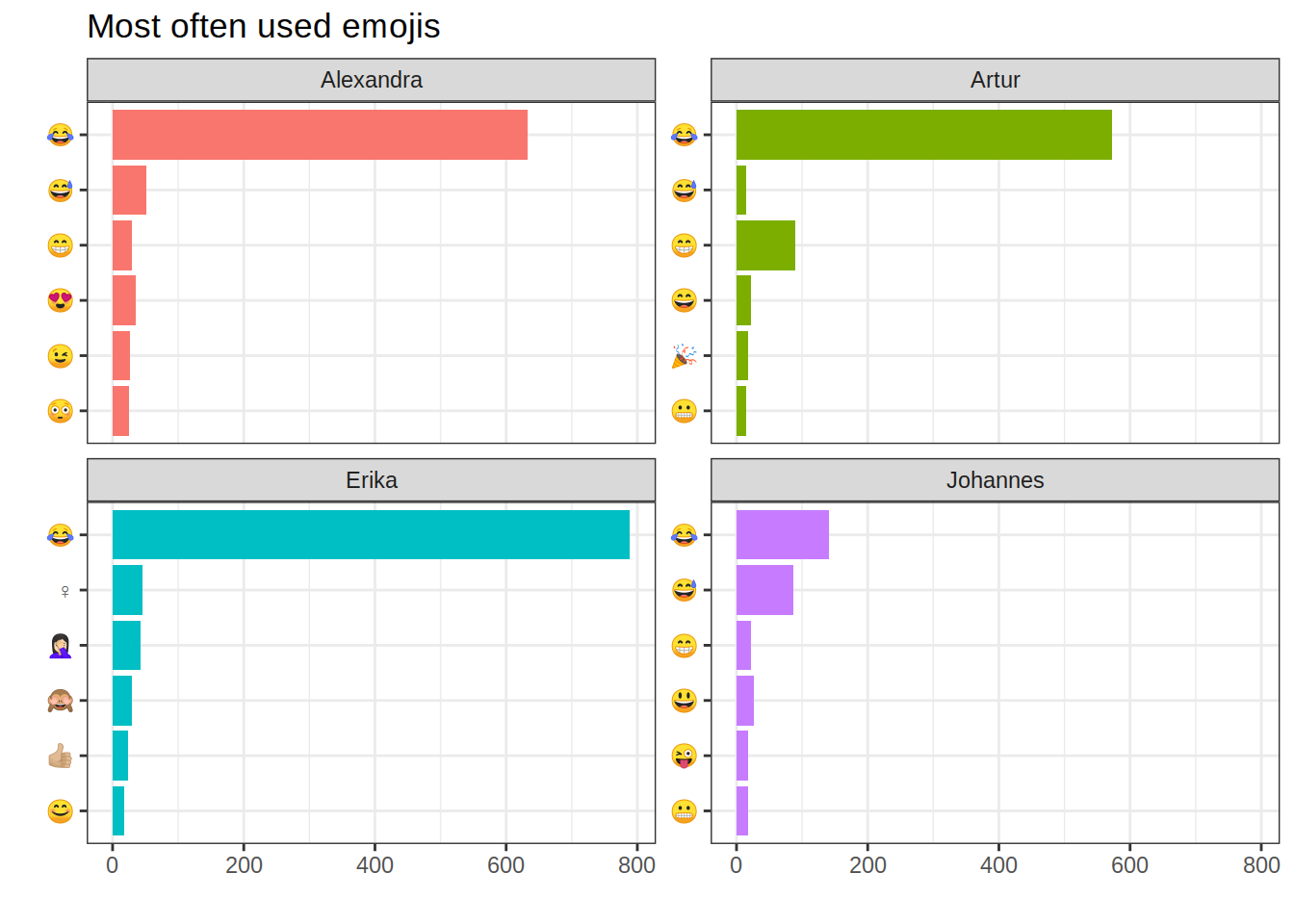
One thing that is always fun to do is finding out what people’s favourite emojis are:
library("tidyr")
chat %>%
unnest(emoji) %>%
count(author, emoji, sort = TRUE) %>%
group_by(author) %>%
top_n(n = 6, n) %>%
ggplot(aes(x = reorder(emoji, n), y = n, fill = author)) +
geom_col(show.legend = FALSE) +
ylab("") +
xlab("") +
coord_flip() +
facet_wrap(~author, ncol = 2, scales = "free_y") +
ggtitle("Most often used emojis")
Looks like we have a clear winner: all of us like the 😂 (“face with tears of joy”) most. 😅 (“grinning face with sweat”) is also very popular, except with Erika who has a few more flamboyant favourites. I apparently tend to use fewer emojis overall while Erika is leading the field (again).
How does it look if we compare favourite words?
I use the excellent tidytext package to get this task done:
library("tidytext")
chat %>%
unnest_tokens(input = text,
output = word) %>%
count(author, word, sort = TRUE) %>%
group_by(author) %>%
top_n(n = 6, n) %>%
ggplot(aes(x = reorder(word, n), y = n, fill = author)) +
geom_col(show.legend = FALSE) +
ylab("") +
xlab("") +
coord_flip() +
facet_wrap(~author, ncol = 2, scales = "free_y") +
ggtitle("Most often used words")
This doesn’t make much sense. First of all, because we write in German which you might not understand 😉. But it also looks weird that Artur and Erika seem to often use the words “media” and “omitted”. Of course, this is just the placeholder WhatsApp puts into the log file instead of a picture or video. But the other words don’t look particularly useful either. They are what’s commonly called stopwords: words that are used often but don’t carry any substantial meaning. “und” for example is simply “and” in English. “der”, “die” and “das” all mean “the” in English (which makes German pure joy to learn for an English native speaker 😅).
To get around this mess, I remove these words before making the plot again:
library("stopwords")
to_remove <- c(stopwords(language = "de"),
"media",
"omitted",
"ref",
"dass",
"schon",
"mal",
"android.s.wt")
chat %>%
unnest_tokens(input = text,
output = word) %>%
filter(!word %in% to_remove) %>%
count(author, word, sort = TRUE) %>%
group_by(author) %>%
top_n(n = 6, n) %>%
ggplot(aes(x = reorder(word, n), y = n, fill = author)) +
geom_col(show.legend = FALSE) +
ylab("") +
xlab("") +
coord_flip() +
facet_wrap(~author, ncol = 2, scales = "free_y") +
ggtitle("Most often used words")
Still not very informative, but hey, this is just a private conversation, what did you expect? It seems though that we agree with each other a lot, as “ja” (yes) and ok are among the top words for all of us. The antonym “ne” (nope) is far less common and only on Artur’s and Erika’s top lists. I seem to send a lot of links as both “https” and “ref” appear on my top list. Alexandra is talking to or about Erika and me pretty often and Artur is the only one who mentions “euro” (as in the currency) pretty often.
Another way to determine favourite words is to calculate the term frequency–inverse document frequency (tf–idf). Basically, what the measure does, in this case, is to find words that are common within the messages of one author but uncommon in the rest of the messages.
chat %>%
unnest_tokens(input = text,
output = word) %>%
select(word, author) %>%
filter(!word %in% to_remove) %>%
mutate(word = gsub(".com", "", word)) %>%
mutate(word = gsub("^gag", "9gag", word)) %>%
count(author, word, sort = TRUE) %>%
bind_tf_idf(term = word, document = author, n = n) %>%
filter(n > 10) %>%
group_by(author) %>%
top_n(n = 6, tf_idf) %>%
ggplot(aes(x = reorder(word, n), y = n, fill = author)) +
geom_col(show.legend = FALSE) +
ylab("") +
xlab("") +
coord_flip() +
facet_wrap(~author, ncol = 2, scales = "free_y") +
ggtitle("Important words using tf–idf by author")
Now the picture changes pretty much entirely. First, the top words of the different authors have very little overlap now compared to before—only exceptions being 9gag (platform to share memes) in Alexandra’s and my messages and “grade” (now) which Artur and I use. This is due to the tf–idf measure which tries to find only words specific to an author.
Now instead of Erika and me, Alexandra talks about Artur, something only she does. Artur is the only one to talk about a Macbook (as he is the only one who owns one). Erika seems to thrive on abbreviations like “oman” (abbreviation for “Oh Mann”/“oh man”, not the country) “eig” (“eigentlich”/actually) “joh” (abbreviation for my name) and curiously “jaa”, which is “ja” (yes) with and unnecessary extra “a”. I show that my favourite adjective is “super” and that I talked about a processor at some point for some reason.
Another common text mining tool is to calculate lexical diversity. Basically, you just check how many unique words are used by an author.
chat %>%
unnest_tokens(input = text,
output = word) %>%
filter(!word %in% to_remove) %>%
group_by(author) %>%
summarise(lex_diversity = n_distinct(word)) %>%
arrange(desc(lex_diversity)) %>%
ggplot(aes(x = reorder(author, lex_diversity),
y = lex_diversity,
fill = author)) +
geom_col(show.legend = FALSE) +
scale_y_continuous(expand = (mult = c(0, 0, 0, 500))) +
geom_text(aes(label = scales::comma(lex_diversity)), hjust = -0.1) +
ylab("unique words") +
xlab("") +
ggtitle("Lexical Diversity") +
coord_flip()
It appears that I use the most unique words, even though Erika wrote more messages overall. Is this because I use some amazing and unique technical terms? Let’s find out:
o_words <- chat %>%
unnest_tokens(input = text,
output = word) %>%
filter(author != "Johannes") %>%
count(word, sort = TRUE)
chat %>%
unnest_tokens(input = text,
output = word) %>%
filter(author == "Johannes") %>%
count(word, sort = TRUE) %>%
filter(!word %in% o_words$word) %>% # only select words nobody else uses
top_n(n = 6, n) %>%
ggplot(aes(x = reorder(word, n), y = n)) +
geom_col(show.legend = FALSE) +
ylab("") + xlab("") +
coord_flip() +
ggtitle("Unique words of Johannes")
Looking at the top words that are only used by me we see these are words I don’t use very often either. There are two technical terms here: “prozessor” and “webseite” which kind of make sense. I’m also apparently the only one to share links to the German news site zeit.de. The English “i’m” is in there because autocorrect on my phone tends to change the German word “im” (in).
Overall, WhatsApp data is just a fun source to play around with text mining methods. But if you have more serious data, a proper text analysis is also possible, just like with other social media data.